AWS Architecture Blog
Shuffle Sharding: Massive and Magical Fault Isolation
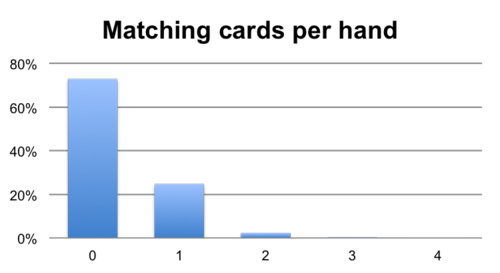
A standard deck of cards has 52 different playing cards and 2 jokers. If we shuffle a deck thoroughly and deal out a four card hand, there are over 300,000 different hands. Another way to say the same thing is that if we put the cards back, shuffle and deal again, the odds are worse than 1 in 300,000 that we’ll deal the same hand again. It’s very unlikely.
It’s also unlikely, less than a 1/4 chance, that even just one of the cards will match between the two hands. And to complete the picture, there’s a less than a 1/40 chance that two cards will match, and much less than a 1/1000 chance that three cards will be the same.
In our last post I promised to cover more about how Route 53 Infima can be used to isolate faults that are request-related, such as user or customer specific problems. Route 53 Infima’s Shuffle Sharding takes this pattern of rapidly diminishing likelihood for an increasing number of matches – a pattern which underlies many card games, lotteries and even bingo – and combines it with traditional horizontal scaling to produce a kind of fault isolation that can seem almost magical.
Traditional Horizontal Scaling
All but the smallest services usually run on more than one instance (though there are some impressive exceptions). Using multiple instances means that we can have active redundancy: when one instance has a problem the others can take over. Typically traffic and requests are spread across all of the healthy instances.
Though this pattern is great for balancing traffic and for handling occasional instance-level failure, it’s terrible if there’s something harmful about the requests themselves: every instance will be impacted. If the service is serving many customers for example, then one busy customer may swamp everyone else. Throttling requests on a per-customer basis can help, but even throttling mechanisms can themselves be overwhelmed.
Worse still, throttling won’t help if the problem is some kind of “poison request”. If a particular request happens to trigger a bug that causes the system to fail over, then the caller may trigger a cascading failure by repeatedly trying the same request against instance after instance until they have all fallen over.
Sharding and Bulkheads
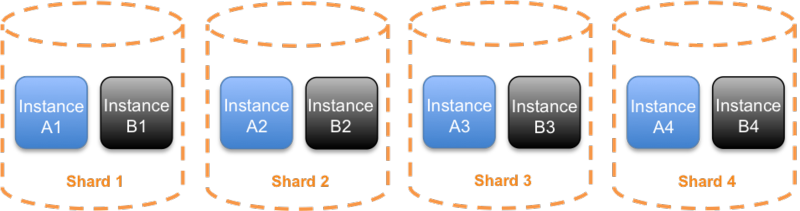
One fault isolating improvement we can make upon traditional horizontal scaling is to use sharding. Sharding is a technique traditionally used with data storage and indexing systems. Instead of spreading traffic from all customers across every instance, we can divide the instances into shards. For example if we have eight instances for our service, we might create four shards of two instances each (two instances for some redundancy within each shard).
Next we face the decision of how to shard. One common way is by customer id, assigning customers to particular shards, but other sharding choices are viable such as by operation type or by resource identifier. You can even choose to do multidimensional sharding, and have customer-resource pairs select a shard, or customer-resource-operation-type.
Whatever makes the most sense for a given service depends on its innards and its particular mix of risks, but it’s usually possible to find some combination of id or operation type that will make a big difference if it can be isolated.
With this kind of sharding in place, if there is a problem caused by the requests, then we get the same kind of bulkhead effect we have seen before; the problem can be contained to one shard. So in our example above, with four shards then around one quarter of customers (or whichever other dimension has been chosen) may be impacted by a problem triggered by one customer. That’s considerably better than all customers being impacted.
If customers (or objects) are given specific DNS names to use (just as customers are given unique DNS names with many AWS services) then DNS can be used to keep per-customer cleanly separated across shards.
Shuffle Sharding
With sharding, we are able to reduce customer impact in direct proportion to the number of instances we have. Even if we had 100 shards, 1% of customers would still experience impact in the event of a problem. One sensible solution for this is to build monitoring systems that can detect these problems and once detected re-shard the problem requests to their own fully isolated shard. This is great, but it’s a reactive measure and can usually only mitigate impact, rather than avoid it in the first place.
With Shuffle Sharding, we can do better. The basic idea of Shuffle Sharding is to generate shards as we might deal hands from a deck of cards. Take the eight instances example. Previously we divided it into four shards of two instances. With Shuffle Sharding the shards contain two random instances, and the shards, just like our hands of cards, may have some overlap.
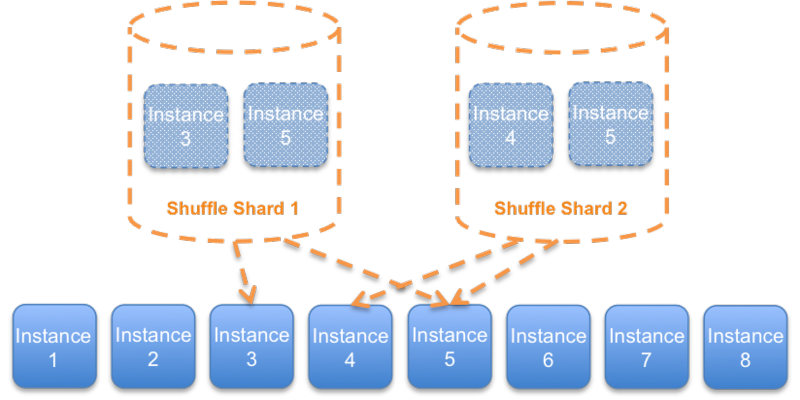
By choosing two instances from eight there are 56 potential shuffle shards, much more than the four simple shards we had before.
At first, it may seem as if these Shuffle Shards are less suited to isolating faults; in the above example diagram, two shuffle shards share instance 5, and so a problem affecting that instance may impact both shards. The key to resolving this is to make the client fault tolerant. By having simple retry logic in the client that causes it to try every endpoint in a Shuffle Shard, until one succeeds, we get a dramatic bulkhead effect.
With the client trying each instance in the shard, then a customer who is causing a problem to Shuffle Shard 1, may impact both instance 3 and instance 5 and so become impacted, but the customers using Shuffle Shard 2 should experience only negligible (if any) impact if the client retries have been carefully tested and implemented to handle this kind of partial degradation correctly. Thus the real impact is constrained to 1/56th of the overall shuffle shards.
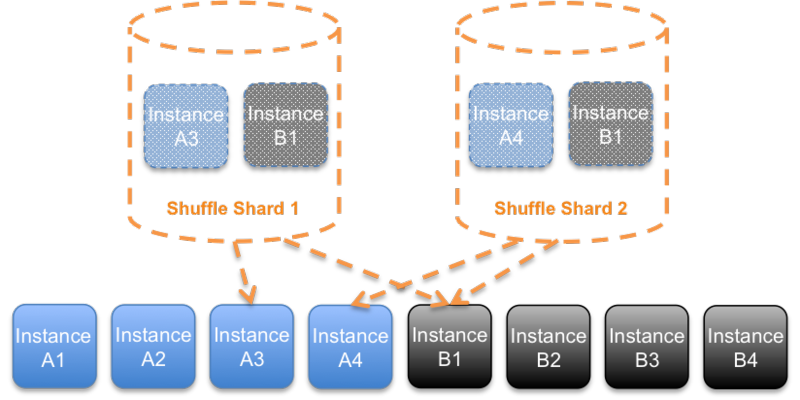
1/56 impact is a great improvement on 1/4, but we can do even better still. Before, with simple sharding we needed to put two instances in each shard to have some redundancy. With Shuffle Sharding – as in traditional N+1 horizontal scaling – we have more instances available. We can shard to as many instances as we are willing to retry. With 3 retries – a common retry value – we can use four instances in total per shuffle shard.
With four instances per shuffle shard, we can reduce the impact to 1/1680 of our total customer base and we’ve made the “noisy neighbor” problem much more manageable.
Infima and Shuffle Sharding
The Route Infima library includes two kinds of Shuffle sharding. The first kind is simple stateless shuffle sharding. Stateless shuffle sharding uses hashing, much like a bloom filter does, to take a customer, object or other identifiers and turn it into shuffle shard pattern. This technique results in some probability of overlap between customers, just as when we deal hands from a deck of cards. But by being stateless, this kind of shuffle sharding can be easily used, even directly in calling clients.
The second kind of Shuffle Sharding included is Stateful Searching Shuffle Sharding. These shuffle shards are generated using random assignment, again like hands from a deck of cards, but there is built in support for checking each newly generated shard against every previously assigned shard in order to make guarantees about overlap. For example we might choose to give every shuffle shard 4 out of 20 endpoints, but require that no two shuffle shards ever share more than two particular endpoints.
Both kinds of shuffle sharding in Infima are compartmentalization aware. For example, we can ensure that shuffle shards also make use of every availability zone. So our instances could be in 2 availability zones, 4 in each one. Infima can make sure to choose 2 endpoints from each zone, rather than simply 2 at random (which might choose both from one availability zone).
Lastly, Infima also makes it easy to use Shuffle Shards along with RubberTrees, so that endpoints can be easily expressed in DNS using Route 53. For example, every customer can be supplied their own DNS name, which maps to a shuffle shard which is handled by a RubberTree.
Post-script
The two general principles at work are that it can often be better to use many smaller things as it lowers the cost of capacity buffers and makes the impact of any contention small, and that it can be beneficial to allow shards to partially overlap in their membership, in return for an exponential increase in the number of shards the system can support.
Those principles mean that Shuffle Sharding is a general-purpose technique, and you can also choose to Shuffle Shard across many kinds of resources, including pure in-memory data-structures such as queues, rate-limiters, locks and other contended resources.
As it happens, Amazon Route 53, CloudFront and other AWS services use compartmentalization, per-customer Shuffle Sharding and more to provide fault isolation, and we will be sharing some more details about how some of that works in a future blog post.
Update from the author: an earlier version of this blog post used an incorrect figure for the number of 4-card hands from a 52-card deck (I wrote 7 million, based on permutations, instead of 300,000 based on combinations).